How to Write an AI Prompt for Product Specs (2026 Guide)
A product spec prompt for AI agents is a structured, version-controlled specification that tells an autonomous coding agent what to build, in what order, and under what constraints. It replaces ad-hoc "vibe coding" prompts with phase-based, test-driven instructions. Done well, it lifts complex-task pass rates by double digits and prevents silent regressions.
Table of Contents:
- Key Takeaways
- Introduction
- Why Did Vibe Coding Stop Working at Scale?
- What Makes an AI Prompt Actually Agent-Friendly?
- Which Frameworks Run Spec Prompts Best in 2026?
- How Should You Tune Prompts for Cursor, v0.dev, and Bolt.new?
- What Security Risks Hide Inside an Innocent AI Prompt?
- The Five-Step Workflow for Writing a Product Spec Prompt
- Honest Tradeoffs
- FAQ
Key Takeaways
- The 20% productivity boost developers feel from AI coding tools is real. The 19% velocity loss on complex work that comes with it is also real, and most teams never measure the second number.
- The spec prompt that actually works for autonomous agents has more in common with a legal contract than a PRD. The structural choices matter more than the wording.
- Three CVEs in 2025-2026 turned the "AI prompt as security perimeter" debate from theoretical to expensive. The defenses your spec mandates determine whether prompt injection stays content or becomes a host compromise.
Introduction
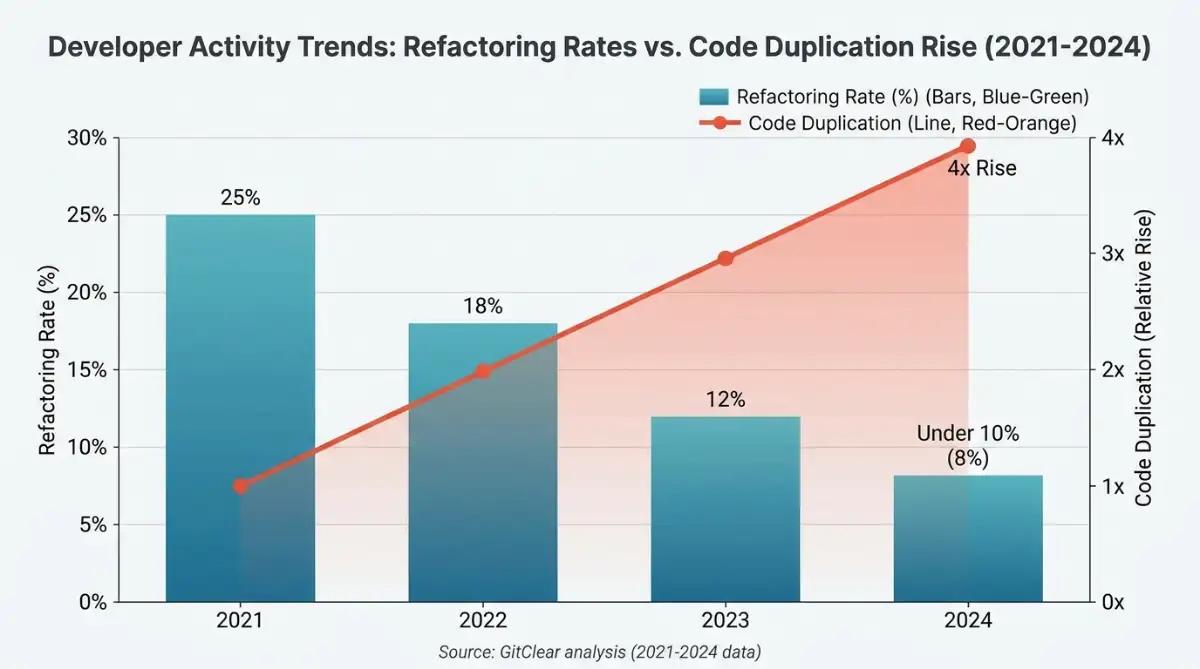
Most non-technical founders shipping with AI coding agents discover the same thing on month three: the agent that built the MVP in a weekend now breaks the codebase every time it touches it. According to GitClear's 2024 code-quality analysis, refactored code dropped from 25% of changed lines in 2021 to under 10% by 2024, while duplication grew fourfold. That is what happens when an AI prompt is treated as a throwaway sentence instead of a contract.
The fix is not better prompts. It's a different category of artifact entirely, and the architecture below is what production teams are actually using to ship reliably with Cursor, Bolt.new, v0.dev, and Claude Code.
Why Did Vibe Coding Stop Working at Scale?
Vibe coding stopped working at scale because every prompt adds entropy and the agent has no contract to check itself against. The term, coined in early 2025, describes the conversational back-and-forth that ships an MVP in an afternoon. According to Martin Fowler's SPDD analysis, unstructured prompting slowed velocity by 19% on complex tasks.
The three failure modes I see most often:
- Context drift. The agent forgets a decision made twelve prompts ago and silently contradicts it.
- Confidence-without-verification. Developers accept generated code without reading it, and silent regressions accumulate.
- The duplication tax. Without a spec, the agent re-implements the same auth flow three different ways across the repo.
There is a reason 61% of large enterprises ran at least one production agent system in 2026, according to IBM and Bessemer industry surveys: they moved past vibe coding the same way the rest of the web moved past table-based layouts. The shortcut becomes the bottleneck.
What Makes an AI Prompt Actually Agent-Friendly?
An agent-friendly AI prompt is not a long paragraph. It is a structured contract with phases, invariants, and acceptance criteria, formatted so the model parses it the same way every run. Traditional PRDs assume a human reader who will fill in gaps using common sense. Agents have none of that.
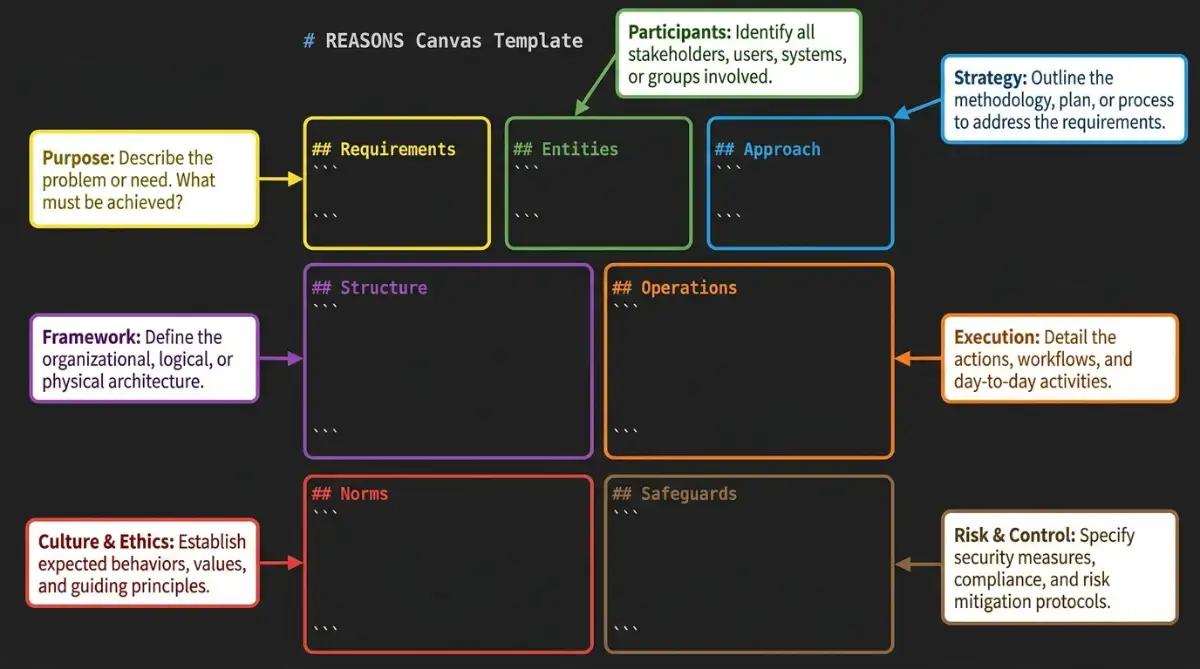
The Thoughtworks Structured Prompt-Driven Development (SPDD) methodology uses what they call the REASONS Canvas: a seven-part structure covering Requirements, Entities, Approach, Structure, Operations, Norms, and Safeguards. A snippet from the methodology looks like this:
## EXPLICIT NON-GOALS (SCOPE OUT)
- No user-facing playlist creation
- No real-time transcription
## SYSTEM INVARIANTS
- Page load time must remain < 2.0 seconds
- Audio buffering latency must remain < 500ms
## ACCEPTANCE CRITERIA
Given a user with "premium" tier access
When they initiate an audio upload request with a valid MP3 file
Then the system must save the file to S3 and return 201 Created
The non-obvious move is the non-goals block. Without it, agents over-engineer. Tell the model what not to build and you cut implementation drift by a noticeable margin in practice. Spec prompts that name the absence are almost always sharper than prompts that only name the presence.
Which Frameworks Run Spec Prompts Best in 2026?
The right framework depends on whether you need auditability, raw throughput, or low-friction onboarding for your team. The four serious contenders in 2026 are LangGraph, CrewAI, Microsoft AutoGen, and Smolagents, and their tradeoffs are not subtle. Pass rates on complex tasks vary by 13 percentage points across the field, and the highest-starred option is not the highest-scoring one.
| Framework | GitHub Stars | Complex Task Pass Rate | Best For | Primary Risk |
|---|---|---|---|---|
| LangGraph | 28,200 | 62% | Compliance, HITL validation, audit trails | Steep learning curve |
| CrewAI | 47,800 | 54% | Visual workflows, fast onboarding | Breaks on non-linear logic |
| Microsoft AutoGen | 56,600 | 58% | Code generation, conversational planning | In maintenance mode for v1.0 |
| Smolagents | 14,800 | 49% | Local tool compilation, code-as-action | Planning-stage failures |
LangGraph wins on the metric most spec-driven teams care about: explicit checkpoints and node rollbacks. The cited pass-rate gap (62% vs CrewAI's 54%) comes from Pooya Golchian's 2026 benchmark comparison. If your prompts ever touch production data, the eight-point pass-rate difference between LangGraph and CrewAI is worth the design overhead.
GitHub's open-source Spec Kit sits on top of these runtimes and gives you the actual command surface (/speckit.constitution, /speckit.specify, /speckit.plan, /speckit.tasks, /speckit.implement). It is the closest thing to a no-code-style abstraction layer for spec-driven engineering.
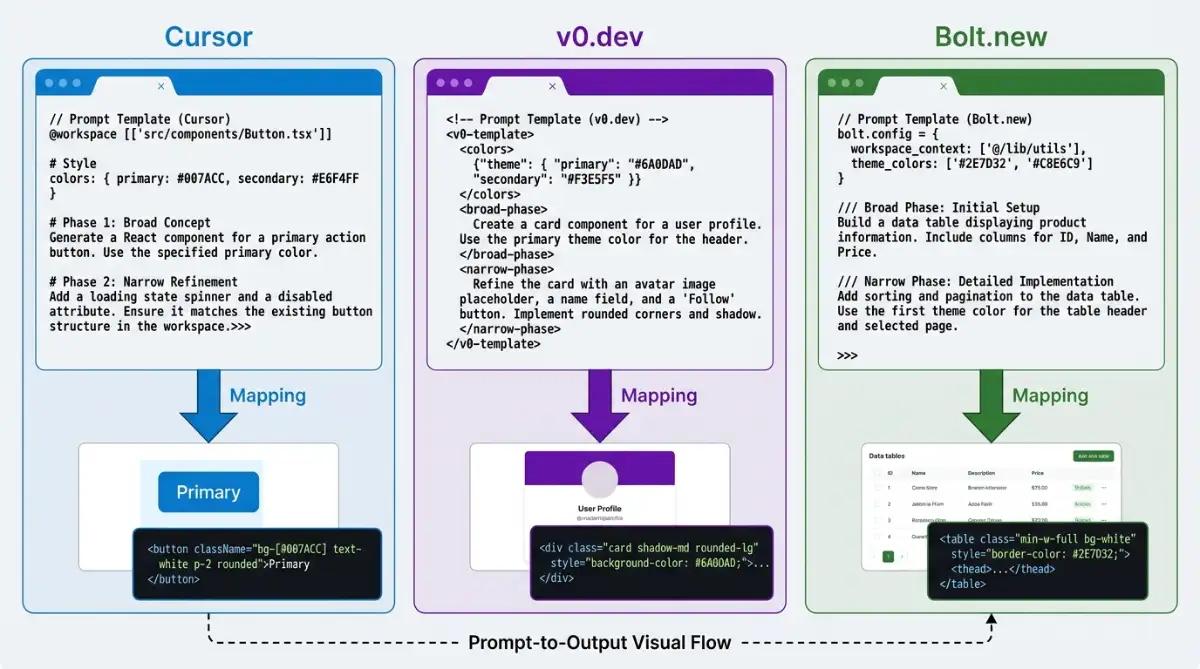
How Should You Tune Prompts for Cursor, v0.dev, and Bolt.new?
Each agent runtime parses prompts differently, so a great spec prompt is also a tool-specific prompt. The same content fails or succeeds based on where you put it and which keywords signal reasoning depth. Cursor wants workspace selectors, v0.dev wants design tokens, Bolt.new wants broad-then-narrow, and Claude Code wants a "think" keyword.
- Cursor indexes your whole workspace. Store specs in
/docs/prd.md, configure.cursorrulesfor global constraints, and in Composer use explicit selectors:Ingest @docs/prd.md and @docs/api-spec.json first. Draft the implementation plan before generating any file modifications. - v0.dev is built for React, Tailwind, and shadcn. Skip subjective language. Specify exact tokens:
Develop a responsive dashboard using dark background #0F0F0F, frosted glass cards, and gradient headers. - Bolt.new boots full stacks in StackBlitz. Open broad (
Establish a Next.js application using SQLite and NextAuth), iterate granularly, and drop a hidden.bolt/promptfile to enforce persistent rules likeAlways use TypeScript.
Claude Code adds a lever most builders miss: the think keyword hierarchy. Use think for routine refactors, think hard for multi-file changes, think harder for schema work, and ultrathink for security-critical migrations. The first time I used ultrathink on a Stripe migration prompt, it caught an idempotency-key bug I would have shipped.
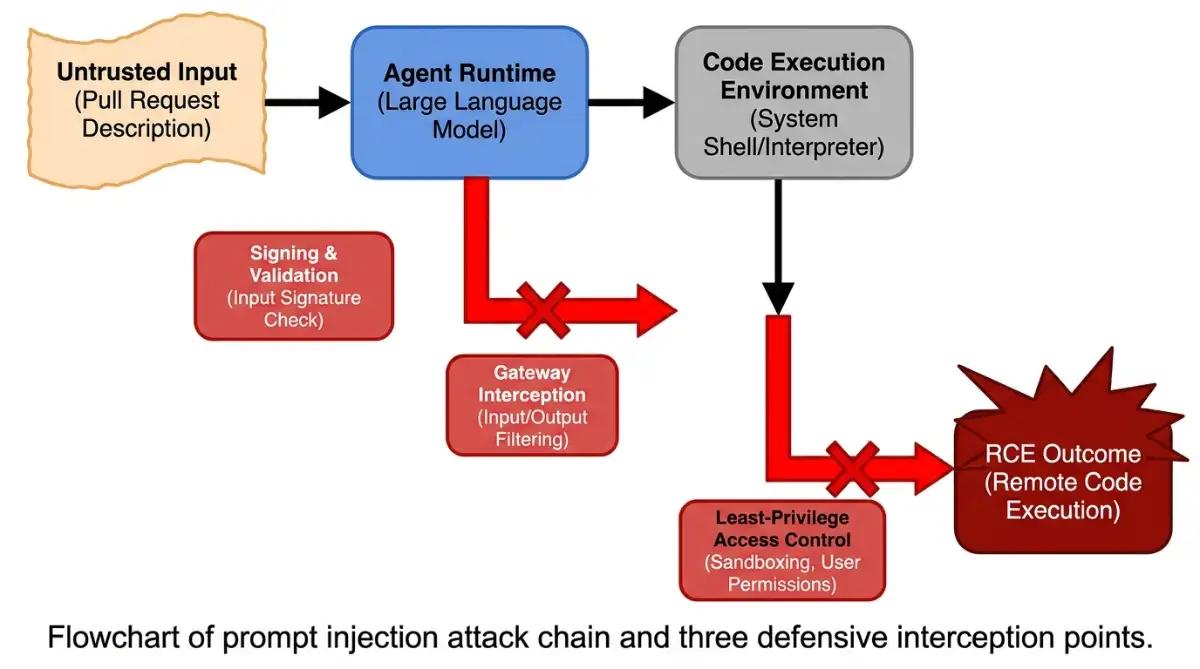
What Security Risks Hide Inside an Innocent AI Prompt?
The moment an agent gains tool execution rights, your AI prompt becomes the security perimeter. Three documented incidents in 2025 and 2026 make the case better than any abstract argument, and the financial premium for getting it wrong is now measurable. According to IBM, breaches involving compromised AI agents cost $670,000 more than non-agentic ones.
- CVE-2025-53773 (GitHub Copilot Agent Mode). Hidden injection payloads in pull request descriptions achieved unauthorized Remote Code Execution inside developer workspaces. CVSS 9.6.
- CVE-2026-26030 (Microsoft Semantic Kernel). An unsanitized injection payload passed into a default vector search plugin and reached host-level RCE.
- EchoLeak (Microsoft 365 Copilot). A zero-click attack silently exfiltrated enterprise mail and document data from connected mailboxes.
The full IBM figure: breaches involving compromised "shadow" AI agents cost $4.63 million on average. The premium comes from invisibility: only 24.4% of enterprises maintain full visibility into agent-to-agent communication, per AGAT Software's 2026 survey, and over 50% of active agents run without formal security logging. The vulnerability sits in how LLMs parse text: system instructions and user-controlled data arrive as a single undifferentiated stream, so the model cannot reliably tell developer intent from a payload hiding in scraped content or a pull request body.
The defenses your spec prompt must mandate:
- Cryptographic prompt signing. Approved prompts are signed with an enterprise private key; the runtime verifies before execution. Injection breaks the signature and halts the run.
- Least-privilege tool access. Agents get only the permissions for the active phase. No hardcoded credentials in prompt text, ever.
- AI Agent Gateways. Tool calls route through an intermediate gateway that scores risk and blocks destructive actions unless a human approves.
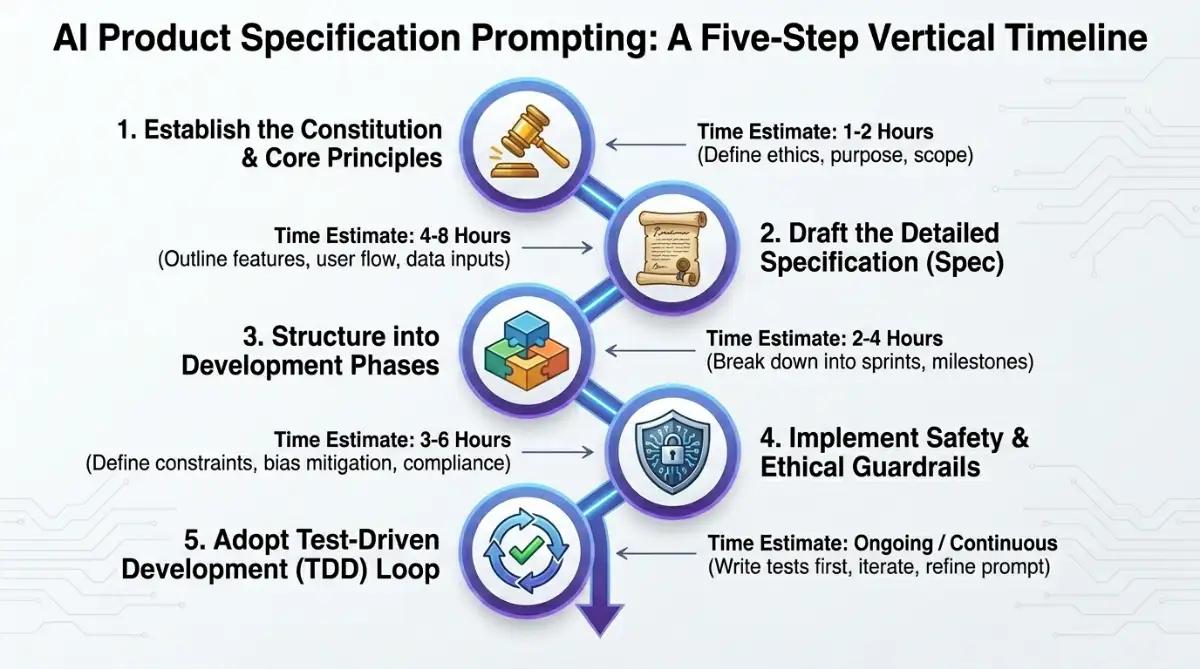
The Five-Step Workflow for Writing a Product Spec Prompt
This is the workflow I use, distilled from GitHub Spec Kit's five-command flow and the SPDD methodology. It takes roughly two hours for a feature spec the first time and fifteen minutes once your constitution is locked. Each step has a verifiable exit condition before the next begins, which is the whole point.
- Establish the project constitution. Write
constitution.md: approved tech stack (e.g., Next.js 14, TypeScript 5.1), naming conventions, library governance (Zustand approved, Redux banned), testing framework, code coverage target. - Formulate the system-first specification. In
spec.md, write Background, System Capabilities, Relational Data Schema, and an explicit Non-Goals list. Skip user stories. The agent needs system realities. - Decompose into dependency-ordered phases. Phase 1: schema and migrations. Phase 2: backend API and integration tests. Phase 3: business logic. Phase 4: UI. Phase 5: error handling and performance. Lock each before starting the next.
- Embed adaptive guardrails. Instead of static rules, instruct the agent to query the repo: "Does this application already use an approved validation framework (e.g., Pydantic, Spring Security)? If yes, use the existing pattern." The same pattern applies to KMS providers and logging frameworks.
- Execute via a TDD loop. Tests first, code second. Run in a local container. Refactor until verification passes against the spec's acceptance criteria.
The single biggest mindset shift here is the same one WordPress made in 2003: treat the source artifact (then themes, now specs) as the durable truth and the rendered output (then HTML, now code) as a derivative.
Honest Tradeoffs
Spec-driven prompting is not a free lunch, and pretending otherwise is how teams get burned.
The upfront cost is real. Writing a proper constitution and spec for a small feature can take longer than just letting an agent freestyle the first version. For throwaway prototypes, that overhead is wasted. The method pays off when code outlives the original session, not before.
Declarative frameworks have a compile-stage tax. Stanford's DSPy optimizes prompts programmatically using compilers like BootstrapFewShot and MIPROv2, but each loop burns thousands of tokens. The cost amortizes over a production lifecycle. For a side project that may never reach production, it does not.
Spec-driven development is not a silver bullet. As Reddit's r/SpecDrivenDevelopment community has noted, specs do not magically resolve ambiguous requirements. Garbage specifications produce garbage code, just more reliably. The discipline shifts the failure mode upstream; it does not eliminate it.
The "single source of truth" rule is brutal in practice. No hotfixes in code: every change goes through the spec first. Most teams break this rule within two weeks and drift back toward vibe coding. The teams that hold the line ship more reliably.
Start exploring launch-ready no-code templates here!
FAQ
What is a product spec prompt? Think of it as a contract between you and the agent, not a wishlist. The format borrows from Test-Driven Development and ISO-style requirements specs: explicit phases, system invariants, and Given-When-Then acceptance criteria, all kept in version control alongside the code it produces.
Is a spec prompt the same as a PRD? No. PRDs target human readers and rely on implicit context. Spec prompts are written for agents lacking common-sense reasoning, so they use explicit non-goals, sequential phases, and Given-When-Then acceptance criteria.
Which AI agent framework should a small team start with? For most small teams shipping production features, LangGraph offers the best reliability-to-complexity ratio with a 62% complex-task pass rate per Pooya Golchian's 2026 benchmarks. CrewAI is easier to learn but breaks on non-linear workflows. AutoGen v1.0 is in maintenance mode.
Can I use spec prompts with no-code builders? Partially. No-code platforms like Webflow and Bubble do not consume spec prompts directly, but the discipline of writing non-goals, invariants, and acceptance criteria still sharpens what you build. For full-stack agent runtimes like Bolt.new, spec prompts are directly executable.
How much does prompt injection actually cost businesses? According to IBM's Cost of a Data Breach Report, security breaches involving compromised AI agents averaged $4.63 million per incident, roughly $670,000 more than non-agentic breaches. The premium comes from limited operational visibility and excessive default tool privileges granted to agents.
Start building without code
Browse thousands of no-code templates for Webflow, Framer, Bubble, Lovable, Replit and more.
Explore Templates